

What Is a Decision Tree and How Does It Work?

28 February, 2025
Share this article
Table of Contents
Let’s be realistic—decision-making is hard. If life came with a cheat sheet that had a definite instruction on what to do at every turning point, I would use it. Well, in data science, there is a cheat sheet, and it’s called a decision tree.
If you’ve ever read a “Choose Your Own Adventure” book as a kid, you already have a rough idea of how decision trees work. They break down complex problems into smaller, more manageable steps, guiding you to a conclusion based on your choices.
A decision tree is a flowchart with a purpose. It starts at a root node (the big question), branches out into possible choices, and ends with small leaves (final outcomes). Businesses use them to predict what people will buy, doctors use them to identify diseases, and banks use them to decide whether you get that loan—or not (and bye-bye to that Lamborghini… sigh).

Photo: © Pluria
One of the best things about decision trees is that they’re easy to understand. Unlike those subtle machine learning techniques that are some sort of magic, decision trees really show you the logic that goes into a decision.
But they are not without flaws—sometimes, they get too excited and start picking up on spurious patterns (this is called overfitting). Fortunately, the problem can be solved, e.g., by pruning (cutting off the parts that are not needed) or by using ensemble methods (blending various trees to create a more potent outcome).
In this article, we will break down everything you need to know about decision trees: what they are, how they work, and where you can use them.
What Is a Decision Tree
A decision tree is basically a flowchart for making decisions. It takes a complex problem and breaks it down into a series of simple, step-by-step choices. Every decision leads to a new branch, eventually arriving at an outcome. This makes decision trees super useful for both decision-making and predictive modeling.
At its core, a decision tree has a few key parts:
- Root Node – The starting point, where the first big question is asked.
- Decision Nodes – The points where you make choices based on certain conditions.
- Leaf Nodes – Leaf nodes represent the final outcomes, where the decision-making process ends.

Photo: © Pluria
Each path from the root to a leaf represents a different way of arriving at a decision. Take a medical diagnosis, for example. A decision tree will start with symptoms (root node), then branch into possible conditions (decision nodes), and finally end with a diagnosis (leaf node).
In predictive modeling, decision trees help spot patterns and make predictions based on historical data. They’re used in everything from customer segmentation (figuring out which customers will buy something) to credit risk assessment (deciding if someone should get a loan) and fraud detection (identifying suspicious activity).
The best part? Decision trees are easy to understand and interpret. Unlike complex machine learning models, they actually show you how a decision is made, step by step. That’s why they’re still one of the most widely used tools in data science.
How Does a Decision Tree Work?
A decision tree is a step-by-step guide for making decisions. It starts at the root node, where an initial question is asked. From there, the process moves through decision nodes, each one leading to a new branch based on the answer (should I do this or should I do that?). This continues until the tree reaches a leaf node, which is the final decision.
How It Works – Step by Step
- Start at the Root Node – The process begins with a key question or condition, usually based on an important feature in the dataset.
- Move Through Decision Nodes – At each step, a decision is made, and the data is split accordingly.
- Repeat Until a Leaf Node Is Reached – This continues until the model arrives at a final outcome.
For example, say you’re debating whether to eat chocolate. A decision tree might start by checking your craving level—if it’s high, you dive right in. If it’s low, other factors kick in, like whether you’ve already had dessert or if you’re pretending to cut back on sugar. Only then do you make the final call.
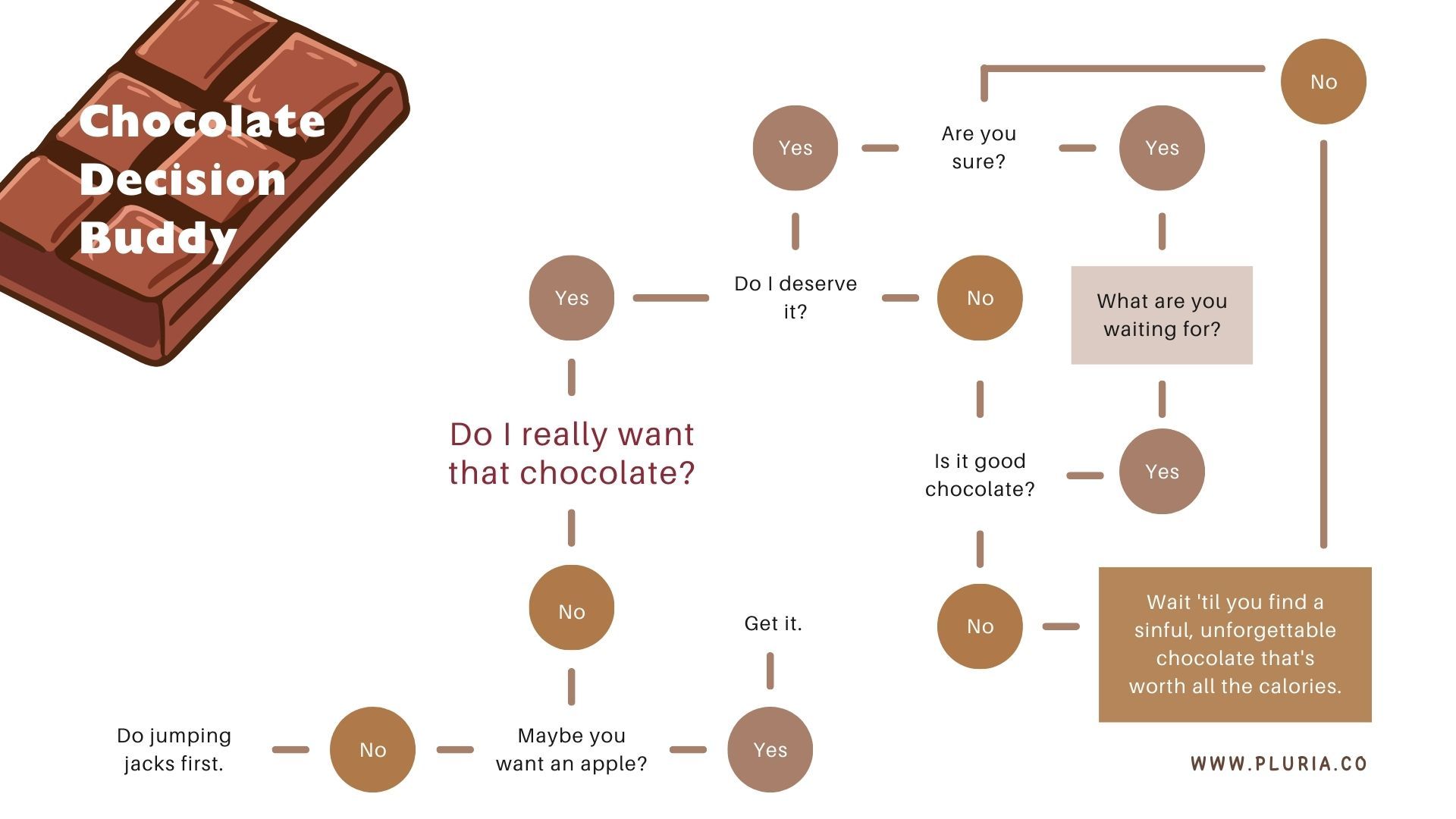
Photo: © Pluria
How the Tree Makes Decisions
At every decision node, the model decides the optimal method to divide the data according to some rules. The rules can be:
- Numerical (Age > 30?) – Dividing based on a number cutoff.
- Categorical (Job Type: Salaried or Self-Employed?) – Dividing based on categories.
The goal is to make the purest split possible so that each branch contains the most similar data points. The most common techniques for this are:
- Gini Impurity – Measures how “pure” each split is. The lower the impurity, the better the split.
- Entropy & Information Gain – Measures how much uncertainty is removed after a split.
Classification vs. Regression Trees
- Classification Trees – Used when the outcome is a category (e.g., “Approve” or “Deny” a loan). The tree sorts data into predefined groups.
- Regression Trees – Used when the outcome is a continuous value (e.g., predicting house prices). Instead of categories, the tree calculates numerical results.
Decision trees are simple but powerful, and therefore, they are a popular choice for decision-making and predictive modeling in any business.
Types of Decision Trees
Decision trees come in two main types: classification trees and regression trees, depending on what kind of problem you’re solving.
Classification Trees
A classification tree is used when the outcome is a category—i.e., it is a member of a specific group. The purpose of the tree is to classify input data into one of these pre-established groups.
Take a spam filter, for example. A decision tree looks at things like keywords, the sender’s address, and the number of links in an email. Based on these, it decides whether the email is “Spam” or “Not Spam.”
Here is how a decision tree classifier operates:
- It chooses the most important feature to split the data.
- It continues to split at every decision node, grouping the instances as separately as possible.
- It identifies a final category (leaf node) when all the conditions are satisfied.
The result is that the tree will learn from patterns in data and place new data points in the correct category.
Regression Trees
A regression tree predicts a value instead of a class. Rather than saying “Spam” or “Not Spam,” it gives you a real value.
For example, if you’re deciding what dessert to have, a regression tree would consider factors like how hungry you are, what sweets you have available, and whether you’re in the mood for something chocolatey or fruity. It breaks down these choices step by step, leading to the best dessert decision.

Photo: © Pluria
Key Difference
- Classification trees predict categories (e.g., “Yes” or “No”).
- Regression trees predict numbers (e.g., a house price of $250,000).
Both types follow the same logic, but they’re designed for different kinds of problems.
Steps to Build a Decision Tree
Decision tree creation is a process to convert raw data into a model capable of making decisions. This is how it works from the beginning to the end.
1. Data Collection and Preparation
First, you need good data—because regardless of how wonderful your model is, if the data is bad, the outcomes will also be bad. This step involves:
- Gather relevant, high-quality data.
- Handle missing values (since real-world data is always incomplete).
- Convert categories to numbers if necessary.
- Normalize numerical data if necessary (though decision trees normally don’t require much scaling).
Use clean and well-organized data as the basis of your decision tree.
2. Choose the Best Features
At each step, the tree must determine which feature to split on. The optimal one is chosen with:
- Information Gain – Displays the quantity of uncertainty eliminated after a split (used in classification problems).
- Gini Index – Quantifies how “pure” a split is (lower is better).
The objective is to focus on the most important features so you can make the best decisions.
3. Divide Data into Sections
Once the best feature is chosen, the dataset is split into subsets. Each new split adds a decision point, refining the classification or prediction more.
For example, if a decision tree is predicting customer churn, it might first split customers based on subscription length, then consider activity levels and support interactions to determine whether the customer will churn.
4. Allow the Tree to Grow (But Not Too Much!)
The tree repeats the data-splitting and feature selection task continuously until it reaches a termination point. It does this to avoid overdoing it and learning noise instead of real trends.
Some stop rules include:
- Maximum Depth – Keeps the tree from turning into an overcomplicated mess.
- Minimum Samples per Node – Makes sure every split actually matters and isn’t based on just a tiny speck of data.
- No More Useful Splits – If splitting further won’t improve accuracy, the tree calls it a day.

Photo: © Pluria
A good decision tree is like a detective—it digs deep enough to uncover real patterns but knows when to stop before it starts seeing clues that aren’t really there.
Popular Decision Tree Algorithms
Over time, different decision tree algorithms were developed to make trees smarter, faster, and more accurate. The most commonly used ones are ID3, C4.5, C5.0, and CART, each with its own way of handling different types of data.
1. ID3 (Iterative Dichotomiser 3)
ID3 is one of the first decision tree algorithms, created by Ross Quinlan. It’s mainly used for classification problems and decides the best feature to split on using entropy and information gain (basically, it looks for the feature that reduces uncertainty the most).
- Good for: Small datasets with categorical variables.
- Not great at: Handling numbers and avoiding overfitting.

Photo: © Pluria
2. C4.5 and C5.0
C4.5 is an improved version of ID3 that works with both categorical and numerical data. It also comes with some useful features:
- Handles missing values instead of just ignoring those rows.
- Prunes the tree (trims unnecessary branches) to prevent overfitting.
- Converts trees into rule-based models, making them easier to interpret.
C5.0 is an upgraded version of C4.5 that’s faster and more memory-efficient, but the core logic stays the same.
3. CART (Classification and Regression Trees)
CART is a powerful algorithm that can handle both classification and regression problems. Unlike ID3 and C4.5, which use entropy, CART relies on:
- Gini index for classification (to measure how “pure” a split is).
- Mean Squared Error (MSE) for regression (to find the best numeric split).
- Good for: Large datasets, both numbers and categories, and works well with pruning.
- Not so great at: Avoiding deep trees if not properly pruned, which can lead to overfitting.
Each of these algorithms has its strengths and weaknesses, but they all help make decision trees more efficient depending on the type of problem you’re solving.
Advantages and Disadvantages
Decision trees are simple and flexible—they don’t need a lot of setup and can handle different types of data. But they have downsides too: they can overcomplicate things, be too sensitive to small changes, and struggle with large datasets if not managed well.
Advantages of Decision Trees

Photo: © Pluria
- They Are Easy to Understand – Decision trees are pretty straightforward. Their flowchart-like structure makes them easy to explain, even to people with no technical background.
- No Need for Feature Scaling – Unlike other machine learning models, decision trees don’t care if your data is on different scales—no need to normalize or standardize anything.
- Handles Both Numbers and Categories – Whether your data is numerical (like age, income) or categorical (like color, job type), decision trees can work with both.
- Minimal Data Prep – You don’t need long hours of data cleaning and transformation—decision trees can handle raw data better than most models.
- Works Well with Non-Linear Relationships – Unlike linear models, decision trees can capture complex patterns and interactions between features without needing extra math tricks.
Disadvantages of Decision Trees
- Prone to Overfitting – If a decision tree grows too deep, it starts memorizing the training data instead of learning real patterns. This means it won’t generalize well to new data. Pruning and ensemble methods like Random Forest can help.
- Sensitive to Small Changes – A tiny tweak in the dataset can completely change the tree’s structure, making decision trees less stable than other models.
- Can Favor Certain Features – If some features have more distinct values, the tree might rely too much on them, leading to biased decisions.
- Computationally Heavy for Large Trees – As the dataset gets bigger, training a deep tree can take a lot of time and memory.

Photo: © Pluria
Alright, let’s crank up the fun:
Sure, decision trees have their quirks, but they’re still MVPs in machine learning. And when you give them a turbo boost—they go from “pretty smart” to “absolute genius.”
Decision Trees vs. Other Machine Learning Models
Decision trees are just one player in the machine learning arena, each model bringing its own strengths and quirks. So, when do they steal the spotlight? Let’s throw them in the ring with logistic regression, random forests, and neural networks to see who comes out on top.
Decision Trees vs. Logistic Regression
- Logistic Regression is like that friend who only thinks in straight lines—it’s great for binary classification but assumes a simple relationship between inputs and outcomes.
- Decision Trees don’t care about straight lines. They’re flexible, handling complex, non-linear patterns like a pro.
When to Pick a Decision Tree: If your data is all over the place with non-linear relationships, tricky feature interactions, or a mix of categorical and numerical variables, the tree’s got your back.
Decision Trees vs. Random Forests
- Random Forests are like a decision tree that brought backup—multiple trees work together to boost accuracy and prevent overfitting.
- Decision Trees are the solo act—simpler, faster, but more prone to overfitting when things get complicated.
When to Pick a Decision Tree: If you need something easy to interpret and you’re working with a small dataset where a single tree can do the job without overcomplicating things.
Decision Trees vs. Neural Networks
- Neural Networks are the deep thinkers of machine learning—great at spotting complex patterns, but they demand a ton of data and computing power.
- Decision Trees keep it simple—easy to understand, less data-hungry, but they struggle when dealing with super high-dimensional problems.
When to Pick a Decision Tree: If you want a model that lays out its reasoning step by step. Neural networks, on the other hand, shine in tasks like image recognition and natural language processing, where patterns are too messy for a rule-based approach.

Photo: © Pluria
When Is a Decision Tree the Best Option?
- When you actually want to understand what your model is doing—clear decision rules, no black-box magic.
- When you’re working with a small to medium dataset and don’t need a computational monster.
- When your data laughs in the face of linear relationships.
- When you’d rather spend less time cleaning and tweaking data and more time getting results.
Decision trees might not always top the accuracy charts, but they’re still one of the most valuable tools in machine learning—especially when clarity and structure matter more than squeezing out every last percentage point of accuracy.
Real-World Applications and Case Studies
Decision trees are a favorite across industries because they’re easy to understand, efficient, and great at simplifying complex decisions. Here’s where they shine:
Business Decision-Making
Companies use decision trees to fine-tune strategies, predict customer behavior, and keep operations running smoothly. Some real-world uses:
- Marketing: Pinpointing which customers are most likely to bite on a campaign.
- Customer Support: Sorting complaints like a pro and finding the best resolution.
- Supply Chain: Figuring out how much inventory to stock without ending up with a warehouse full of regrets.
Healthcare & Medical Diagnosis
Doctors turn to decision trees to diagnose diseases and recommend treatments based on symptoms and medical history. Some examples:
- Cancer Detection: Evaluating tumor size, patient age, and genetic markers to assess cancer risk.
- Disease Prediction: Estimating the likelihood of conditions like heart disease based on medical tests and lifestyle factors.
Decision trees help standardize and speed up medical decision-making, giving doctors a clear, data-driven way to analyze cases—because guesswork doesn’t belong in healthcare.
Finance & Insurance
Banks and insurance companies rely on decision trees to detect fraud and assess risk. Here’s how they put them to work:
- Credit Scoring: Deciding if someone’s a good bet for a loan based on income, credit history, and debt levels.
- Insurance Fraud: Spotting shady claims by analyzing past fraud patterns.
- Cybersecurity: Catching sketchy transactions that don’t fit a user’s usual behavior.
When money’s on the line, decision trees help financial institutions make smarter, faster, and more secure decisions.

Photo: © Pluria
Key Takeaways
- Flexible & Low-Maintenance: Decision trees handle both categorical and numerical data without demanding a ton of preprocessing.
- Versatile & Practical: They shine in business decision-making, healthcare diagnostics, and fraud detection.
- Not Perfect, But Fixable: They can overfit and be sensitive to data changes, but tricks like pruning and ensemble methods (looking at you, Random Forest) help keep them in check.
Next Steps
If you’re curious to see decision trees in action, why not build your own? Python libraries like scikit-learn make it easy to create and train decision tree models. Play around with different datasets, tweak parameters, and see firsthand how these trees split and grow—it’s the best way to truly understand how they work in practice!
Keep up to date with our most recent articles, events and all that Pluria has to offer you.
By subscribing to the newsletter you agree with the privacy policy.

In the last two years I’ve been working remotely from over 20 countries but no part of the world compares to Latin America: countries and cultures spreading over two continents with climates[...]
04 December, 2023

A massive move to hybrid work
In 2022, 60% of companies will switch to a hybrid working model, and a third of them will fail on their first attempt to work from anywhere, Forrester p[...]
04 December, 2023

When the employees in the most innovative company on the planet rally against their CEO because he wants them back in the office three days a week, it is a sign that it is not enough to be innovative in tec[...]
04 December, 2023